

Breaking down Rabbit R1's security issues
It's pretty bad

So, it’s been a bad week for the team behind the Rabbit r1. A group called Rabbitude has disclosed that four API keys were exposed and could have led every r1 responses ever given to be downloaded. Rabbit has since issued a statement about this incident. I wanted to break down this story from a security perspective, what the possible architecture is, what went wrong, and the ways that it could be re-architected in order to fix this issue.
I’m writing this the evening of Thursday, June 27th. So if any news emerges or changes to this story emerge, I may post a follow up.
I’m especially qualified to talk about this topic because I work on security in manufacturing, embedded, mobile app, and cloud contexts. I’m not a master in any, but the variety of my work requires me to frequently speak to each of these areas.
First, let's discuss what we know we know: that four API keys to ElevenLabs, Azure, Yelp, and Google maps were exposed. With these, Rabbitude claims that all of the possible queries that have been made to the system ever and their responses could be exposed. They have also claimed that these API keys could be used to brick all r1 devices and manipulate the responses.
Now, there's two main theories I have on how this system is architected. The first is that on the at rabbit r1 device, which runs an Android APK, that these API keys were hard coded into the APK and then could be used to query each of the services individually. This is really bad from a number of different security perspective to hard code keys in a hardware device that isn’t hardened properly. But this also doesn’t make sense from a business perspective. Rabbit probably can’t build enough hype if its r1 devices just act as a means to access LLM APIs or other useful APIs. There needs to be something more that Rabbit is actually doing.
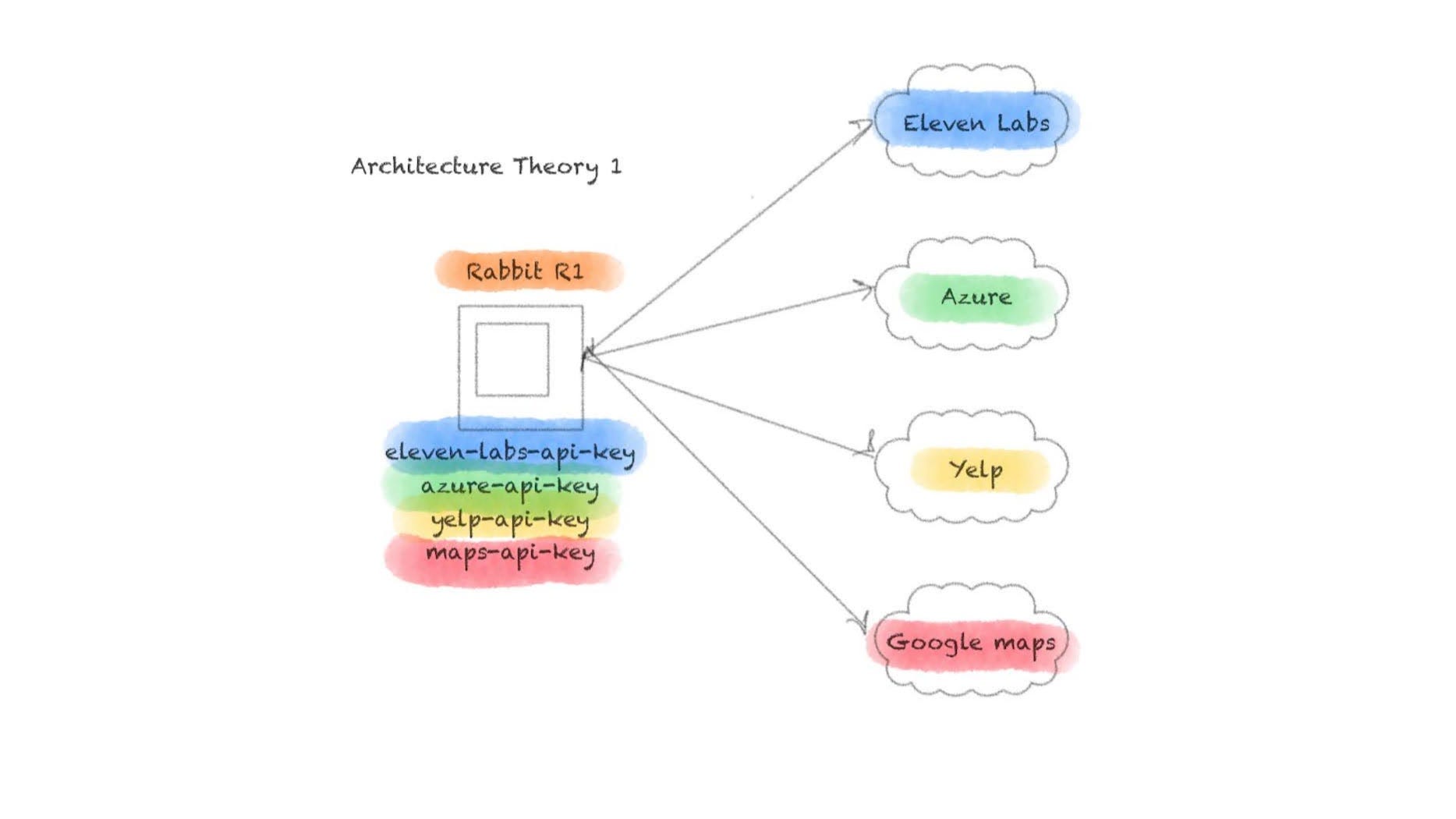
A more plausible explanation is that the API keys being referred to are hard coded to a suite of backend services that r1 connects to. This service may have some if its own LLM capabilities, but nothing ground breaking. This service would connect to third parties to offload some of the work. Text to speech conversion, maps, and local reviews are all competencies that r1 wouldn’t need to reinvent in a gen one product, so it makes sense that these services would be used.
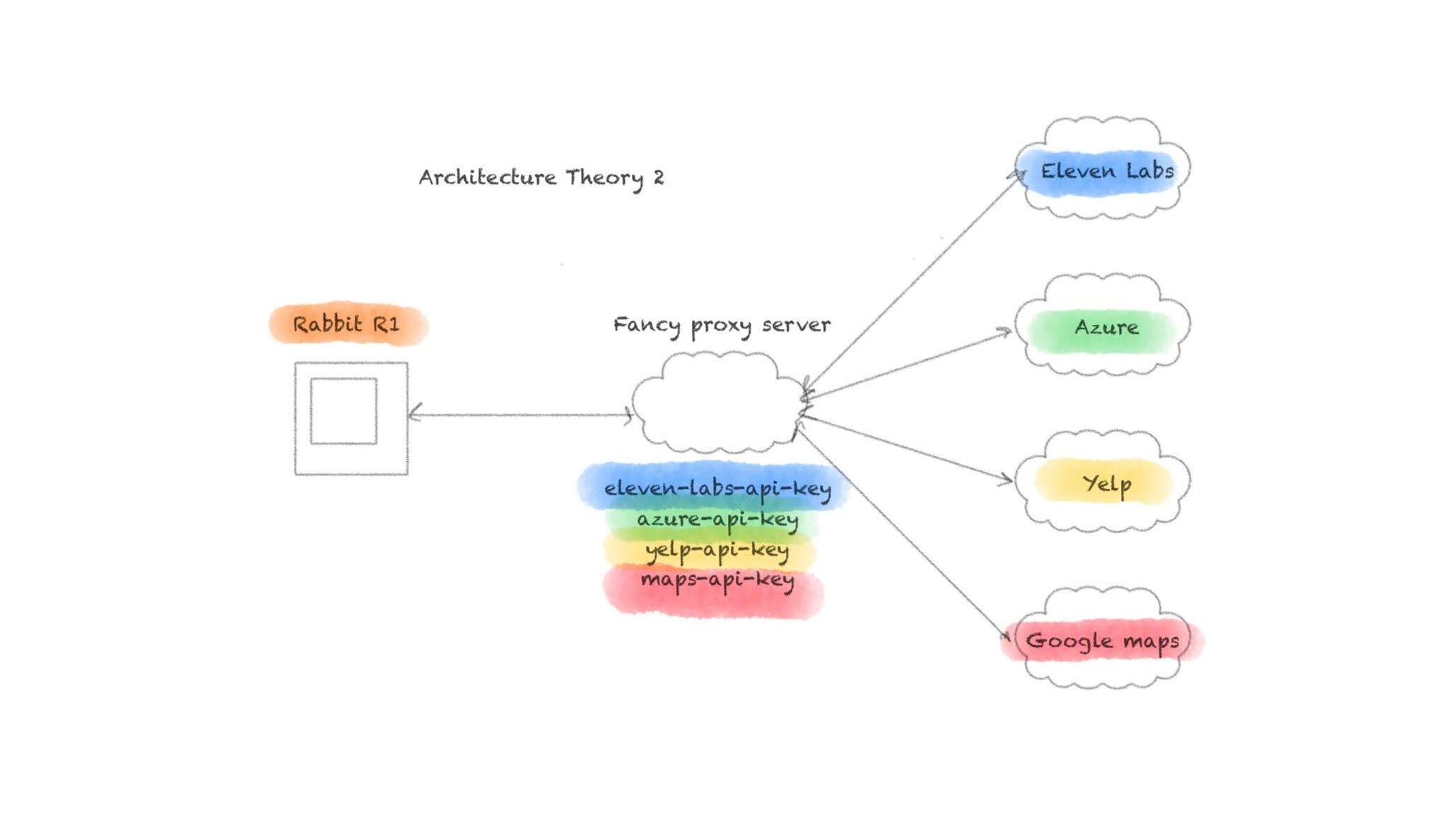
The security researchers claimed that these keys could have been used to brick all r1 devices and edit all responses given to users. This gives me the strong suspicion that our second architecture theory is correct. If each r1 devices connected to the third parties individually, then this attack wouldn’t be possible.
This is not as disastrous as having the credentials hard coded in the APK, but still a screw up
Let’s try to imagine what a more ideal authorization scheme might look like for access. In manufacturing, we want to be loading in certificates that are signed by the company’s dedicated certificate authority. This certificate will serve to authenticate r1 devices to an authorization server that can then provide a JWT. I’m choosing to add this certificate in at manufacturing because I know my device is just an APK. An APK can be extracted from the hardware and put onto a regular Android device. I want a reason that services are only accessible on r1 devices - a unqiue signed certificate provides that.
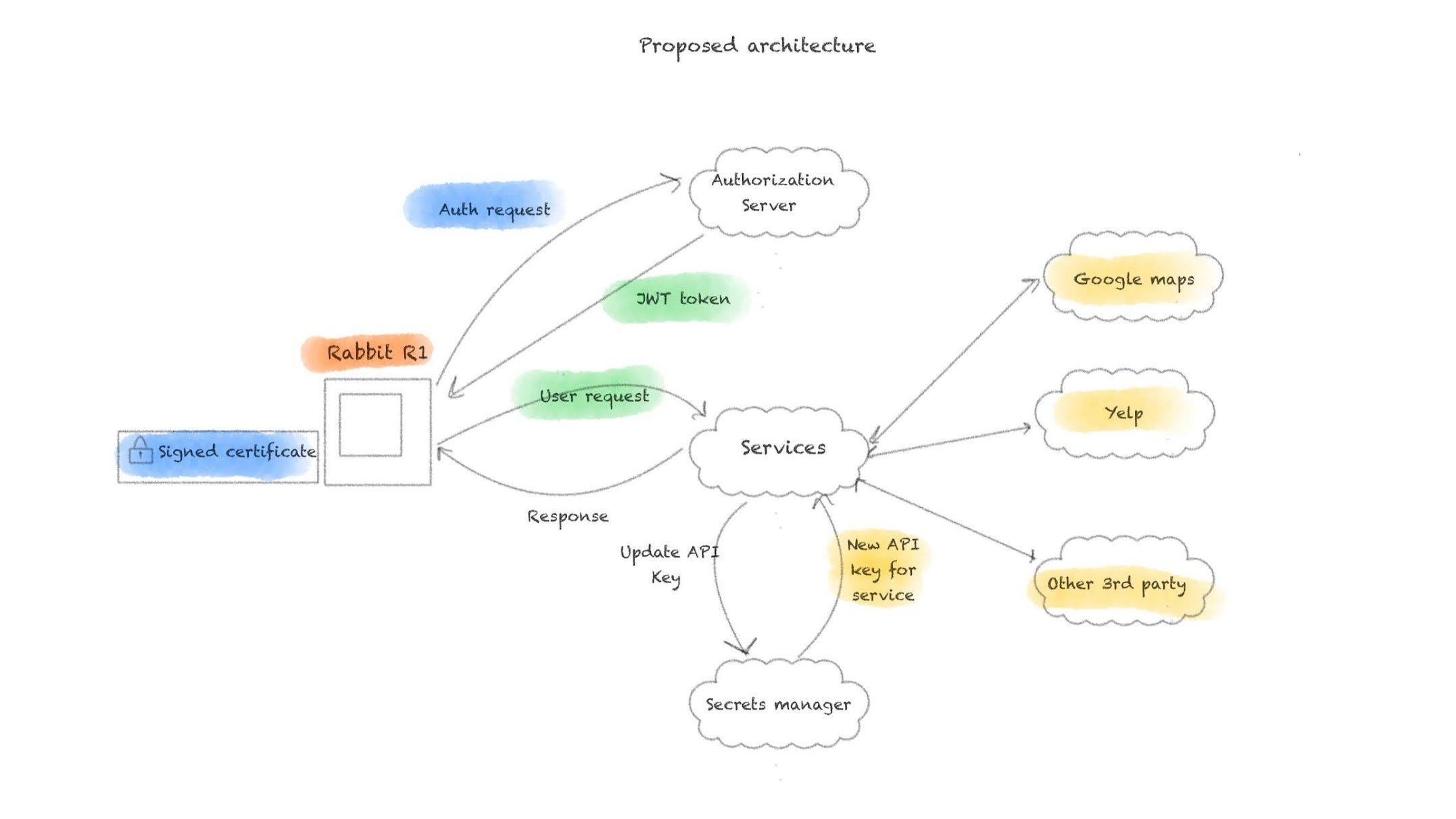
JWTs are a much more effective way of managing access to a backend service at scale. An application gateway normally adjudicates whether or not a user should have permission to the endpoint based on the JWT they provided.
Each service that acts as a wrapper to a third party API should no longer have a hard coded key. Instead, these keys should automatically be rotated and managed through a cloud secrets manager service.
This is the minimum bar. There are still many more flaws I could see in the system depending on the business use cases and what the level of confidence needs to be in the response. But this is the floor.
I think there are a couple reasons why Rabbit r1 would have architected it in a way where all queries go through a singular backend. And that’s so they can collect user data to improve the product. I don’t even have a problem with that! Most people say that with some animosity, but I personally believe that this is something totally reasonable.
LLMs are rife with questions around “should a user be able to generate this content?” This reminds me of the moderation discussion in the late 2010s over social media, which did not age particularly well and resulted in an overly negative privacy bias towards Meta (formerly Facebook) and other big tech companies. Users are going to do questionable things with your product, each company should have their own approach to moderation. If you don’t like it, don’t use their product.
Rabbit could easily allow everything to go through on their AI service to third parties, but they open themselves up to scrutiny once users start using this behavior for questionable activities.
It is good that Rabbit revoked the compromised API key access, but they also need to think about some deeper changes that need to be made in order to improve the security and trust of their system. I think that people want safe and secure devices that respect their privacy, even if they don’t understand how it actually works. Headlines around security compromises do not make users feel secure even if they were not personally affected.
I feel like this is almost punching down because of the near unanimous criticism Rabbit received for the launch of their product. They didn’t make vaporware, they shipped a product. Good job. Now fix it.